
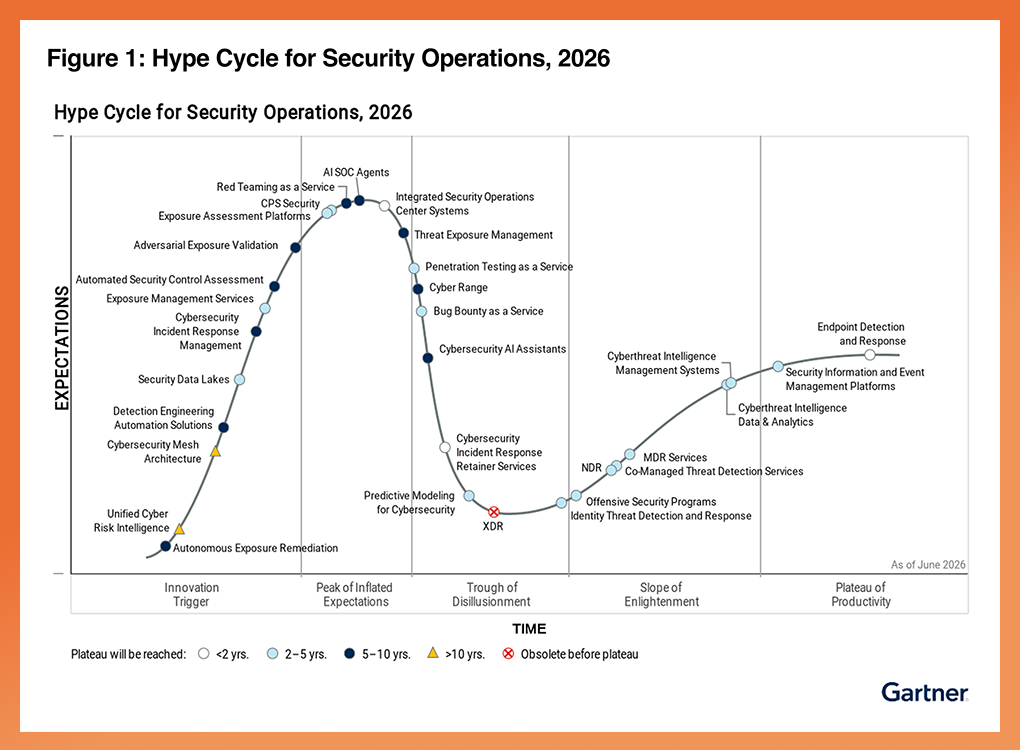


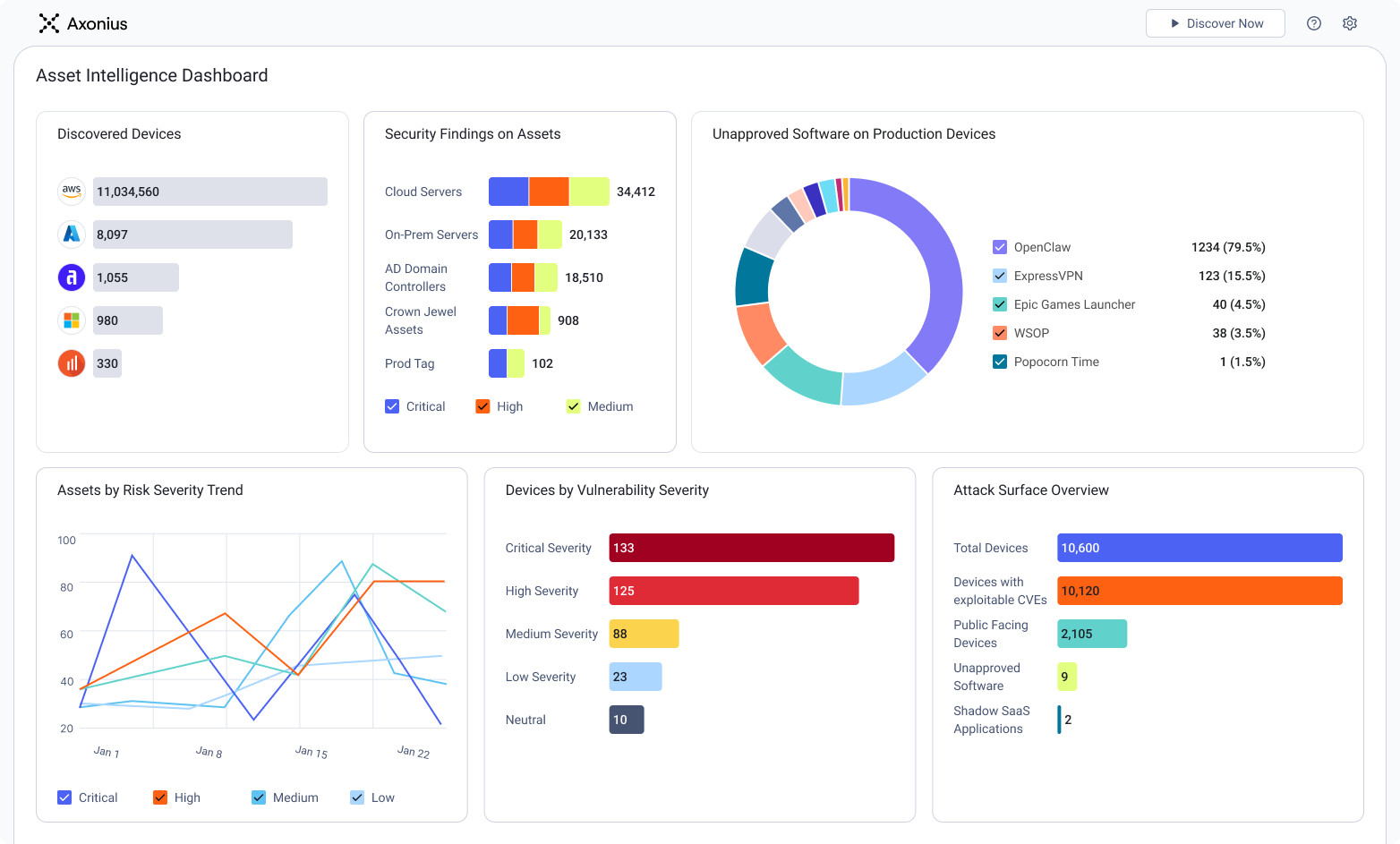
See Axonius in action
See how to make asset intelligence actionable with a guided demo:
- Stop chasing data — work from one asset model your entire team can trust.
- See what's exposed before it's a problem — surface coverage gaps automatically.
- Turn alert noise into action — cut thousands of alerts down, to the ones that matter.