Behind actionability: Adapter Network data trends

Ivan Dwyer
Principal Product Marketing Strategist, Axonius

My prior post in this Behind Actionability blog series detailed the technical architecture of our asset intelligence pipeline, uncovering some of the nuances that make it especially hard to continuously fetch complete, accurate, and up-to-date asset data across the global attack surface. In that post, I made the assertion that a small number of control planes in your IT stack, when effectively aggregated, reveal the full picture of your environment. An MDM agent, an IdP, a vulnerability scanner, a SaaS app: somewhere in your stack, every asset leaves a signal.
This post zooms in on those control planes through the lens of Axonius Adapter Network usage data. When effectively aggregated, adapter connections reveal how teams are using asset intelligence to drive intelligent action.
A note on methodology: Usage data is anonymized and aggregated across a sampling of customers. Adapter data is measured across all customers, based on unique organization environments with active adapter connections.
Actionability in data
In the simplest of terms, the continuous lifecycle of asset intelligence involves discovery, prioritization, and remediation. Each carries a ton of weight and even more considerations. In a perfect world, the end result is resilient, self-healing environments. We don’t live in a perfect world, however. The attack surface is fragmented, teams face too many issues with too little capacity, and actionability has a context dependency that’s often unmet.
Our research looks at this lifecycle in practice. By analyzing adapter usage data, we can see how teams are approaching each stage: where they’re strong, where complexity creeps in, and where opportunities lie to make actionability a reality.
CYA: Cover your agents
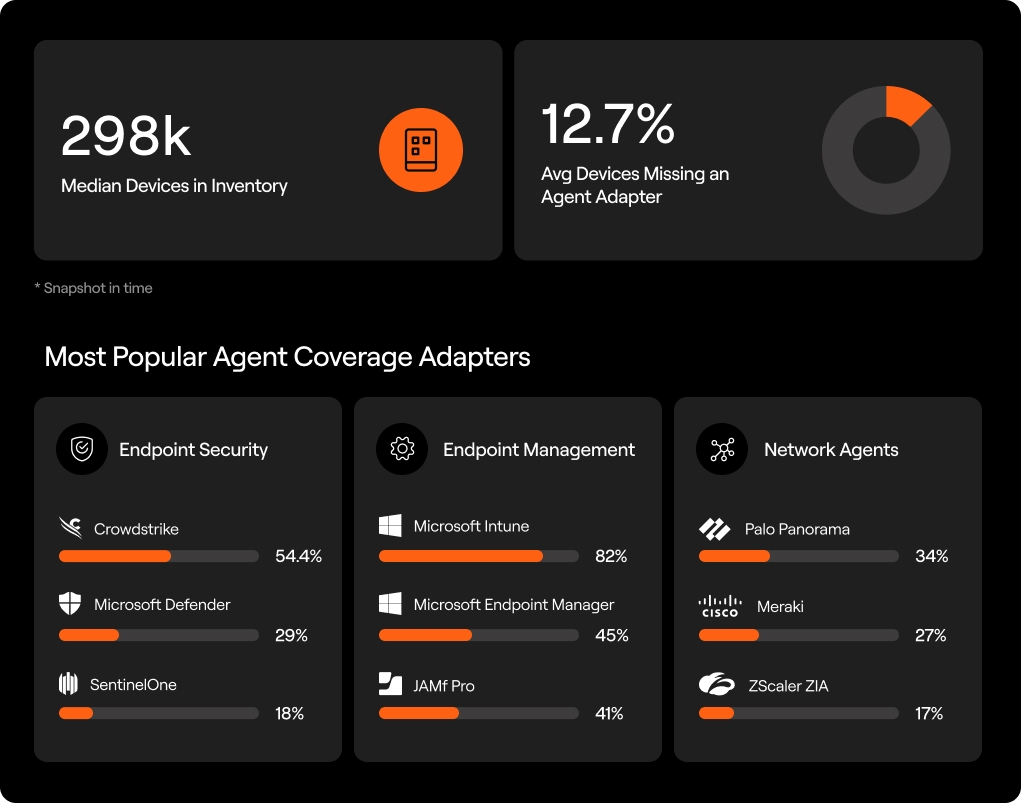
Every cybersecurity team has the same mandate: make sure every device, across every operating system, is covered by the respective monitoring agents. Agent coverage underpins visibility, posture, and response. It’s foundational.
The results
What is immediately apparent is that this is a breadth challenge. With an average of 298k devices under management, full coverage is hard. This includes a wide range of device-centric assets, including workstations, appliances, mobile devices, and more, that all follow their own lifecycle, run on different OSes, are hosted in different places (on-prem, cloud, remotely), are subject to different compliance requirements, and have their own set of characteristics and behaviors. As such, they require different agents to perform different functions. There’s no single agent to rule them all, as the percentages across our install base suggest.
We grouped the most popular agent-centric adapters across devices into three buckets:
Endpoint security: These agents sit directly on the device, monitoring for threats, detecting malicious or anomolous behavior, and enforcing security controls.
Endpoint management: These platforms provide visibility and control over device configurations, software deployment, patch management, remote control, and compliance enforcement. They ensure endpoints stay patched, updated, and aligned to policy.
Network agents: These tools extend visibility and control to the network layer, monitoring traffic, enforcing segmentation, and surfacing unmanaged or rogue devices. They help bridge the connectivity between on-prem, cloud, and remote environments.
Looking at the gaps, the fact that only 12% of devices on average weren’t reporting via an agent is impressive. We wouldn’t suggest that compliance == security; however, most guidelines are written for 80% coverage. So teams using Axonius are doing a good job of exceeding expectations in that regard.
The opportunity
While 12% is a fair gap given the scope of coverage required, there is always room for improvement. Discovery is step one, but let’s put the concept of self-healing environments to the test here. There is a mental model for CTEM that applies here.
Declare what you want to be true: which agents belong on which device sets under which conditions
Detect deviations from the truth: continuously monitor device state for functioning agents reporting data
Decide if the deviation matters: when missing, get surrounding context, impact, and SLAs to make decisions
Deliver actions to restore the truth: automate installation or update flows using available tooling and/or procedures
I’d love to come back next year and report that the number is down from 12% year over year!
Axonius pro tip
The good news is that closing agent coverage gaps is a marquee Axonius use case for many of our customers. Because of the distribution of tools and conditions, however, it’s not a one-size-fits-all solution.
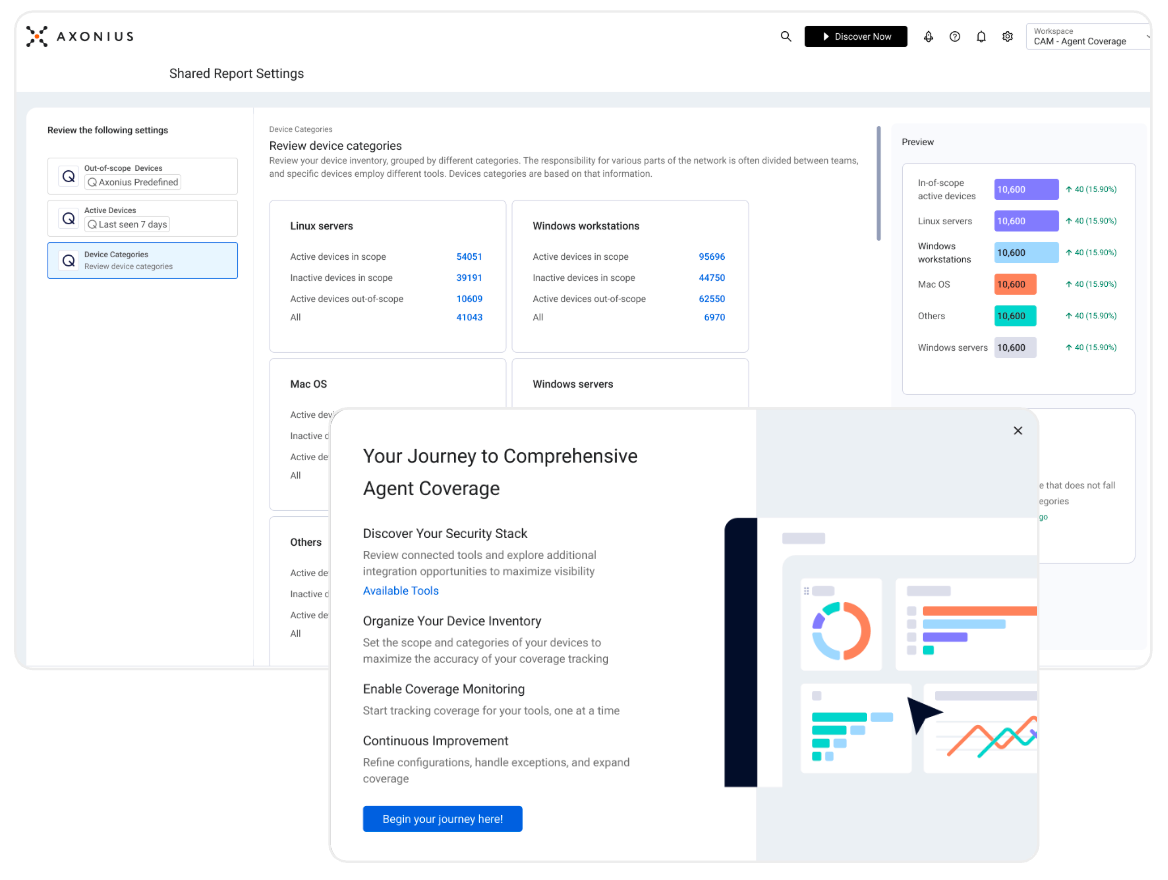
We’ve packaged the most common patterns with guidance on how to tailor to your environment into a workspace, a new feature we released, that allows you to define which agents belong on which devices, and track continuously. Catch a drift? Leverage an action using your deployment method of choice to get it back on and up and running.
Not only will you see that coverage gap diminish, you’ll have confidence in the continuous nature of agent coverage data.
Exposure context exposed
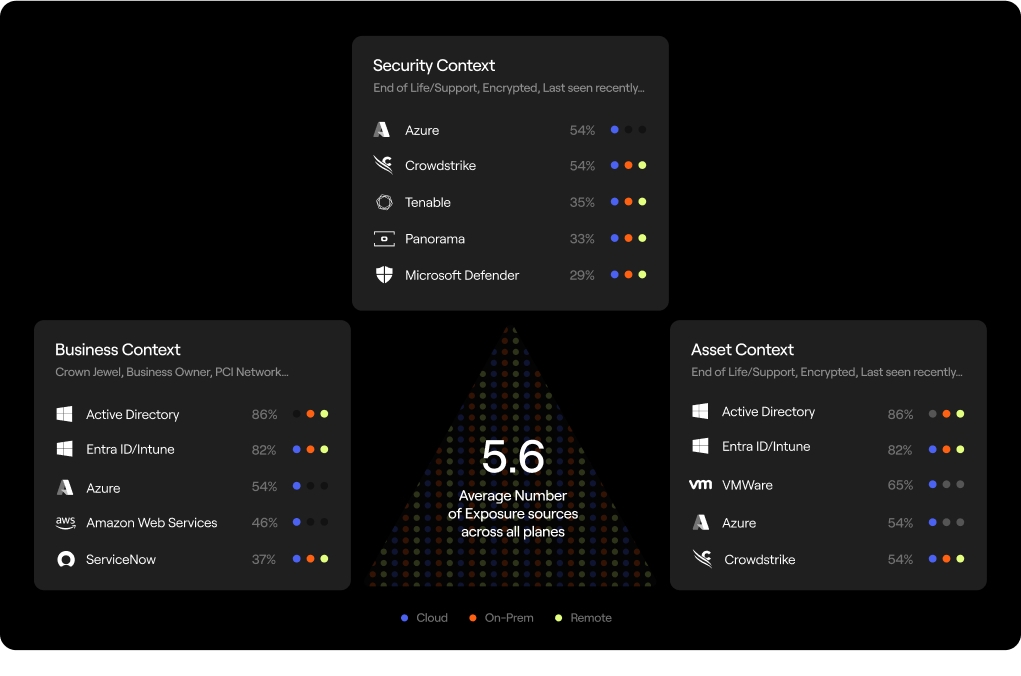
Exposures come in many forms from all angles: vulnerabilities, misconfigurations, and inefficiencies that impact risk, performance, and cost measures. Without the right context, it’s nearly impossible to know which issues truly matter. Context comes from a wide range of sources, and is a mixed bag of security, asset, and business context.
The results
We talk a lot about data fragmentation when it comes to discovery, but it’s also a consideration when it comes to reporting issues and findings. We found that, on average, organizations rely on 5.6 tools to supply context related to known vulnerabilities.
Security context: vulnerability scanners, EDR tools, and cloud security platforms reporting vulnerabilities, misconfigurations, weak controls, and more
Business context: inventories, collaboration tools, and cloud platforms reporting ownership data, compliance tags, criticality, and more
Asset context: identity providers, management systems, and directories reporting device metadata, EOL/EOS data, and more
This isn’t an alarming number of tools supplying context; it’s expected. Identity providers, vulnerability scanners, business systems, cloud providers, and more. Each source contributes important insights, but the danger is that they often exist in siloes. Business context in one tool, security context in another, asset metadata in yet another.
The power of aggregation is illustrated here. Getting all the context is one thing. Connecting the dots is another, especially considering the various deployment models. Some tools focus on discovering cloud vulnerabilities, others support remote workers and machines, while others focus on on-prem infrastructure.
That’s why having all three lenses (asset, business, and security context) in one place, regardless of the plane or whether a vulnerability scanner is installed, is so important. It’s what turns raw findings into something teams can prioritize and act on with confidence.
The opportunity
With many different tools providing varying types and levels of context, good hygiene is key. But have you ever started a data classification project and given up halfway? Or implemented cloud tagging best practices, only to be left with more tag names than S3 buckets? Or mapped ownership across assets to find many unknowns? Don’t worry, it happens to the best of us.
The opportunity here is to consider what I’ll call a self-tagging environment following a similar mental model as our self-healing environment from the prior section. This means applying rules on discovery that look at select pieces of context to then automatically apply the right tags: owner, environment, workload, etc. The idea is that the continuous nature of discovery leads to continuous tagging, rather than trying to slog through a manual project.
Axonius pro tips
If you’re wondering how to do that with Axonius, you’re in luck. Another marquee use case is exactly this, applying Enforcement Actions based on query result changes on discovery cycles.
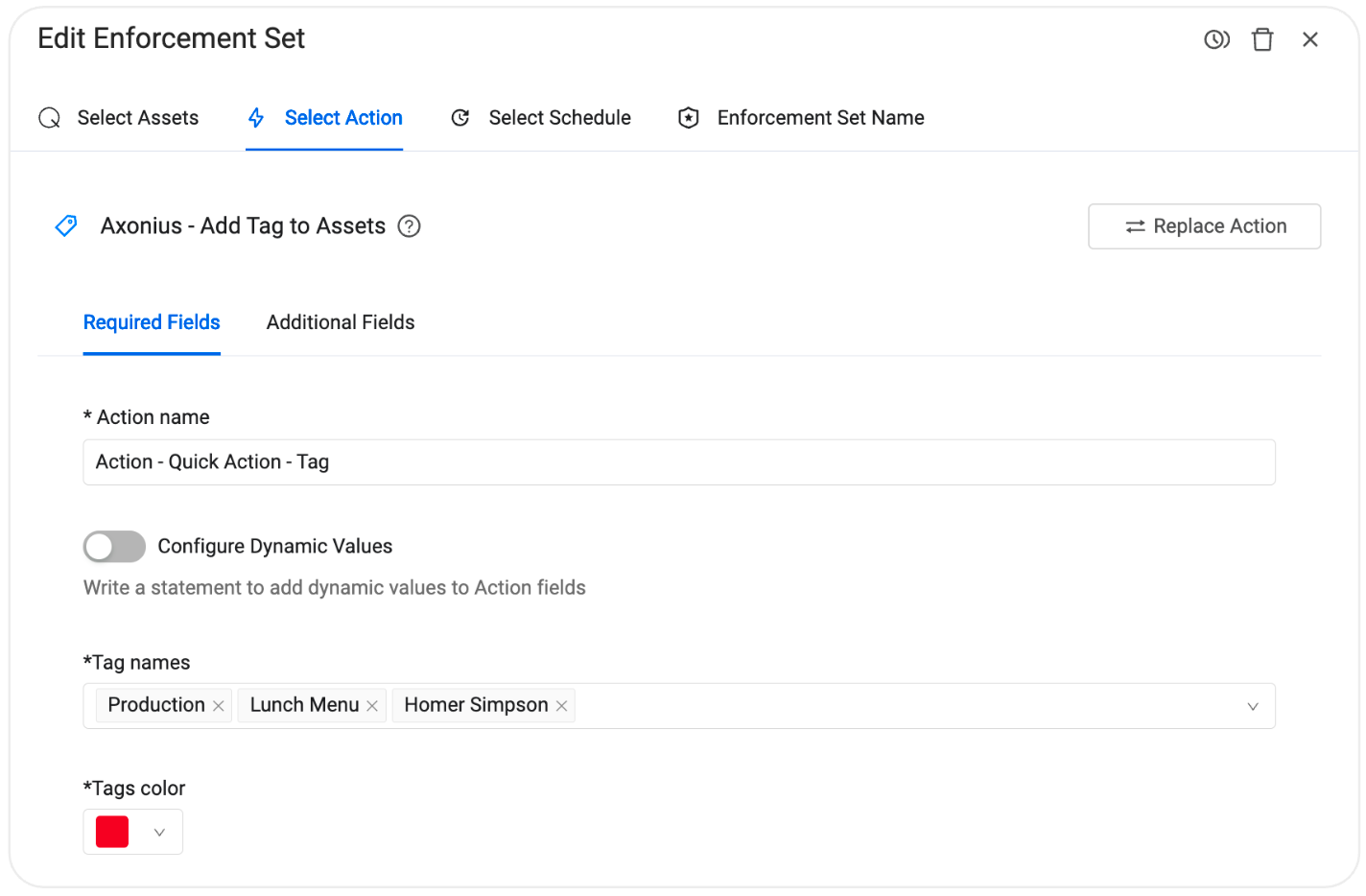
When it comes to prioritization, too many risk scores are opaque. When you see a Risk Score calculated on a Vulnerability Instance in Axonius, you can get the full breakdown: the source, the reason, and the weight. This gives you an actual mental model for effective prioritization, tuned to the intricacies of your environment.
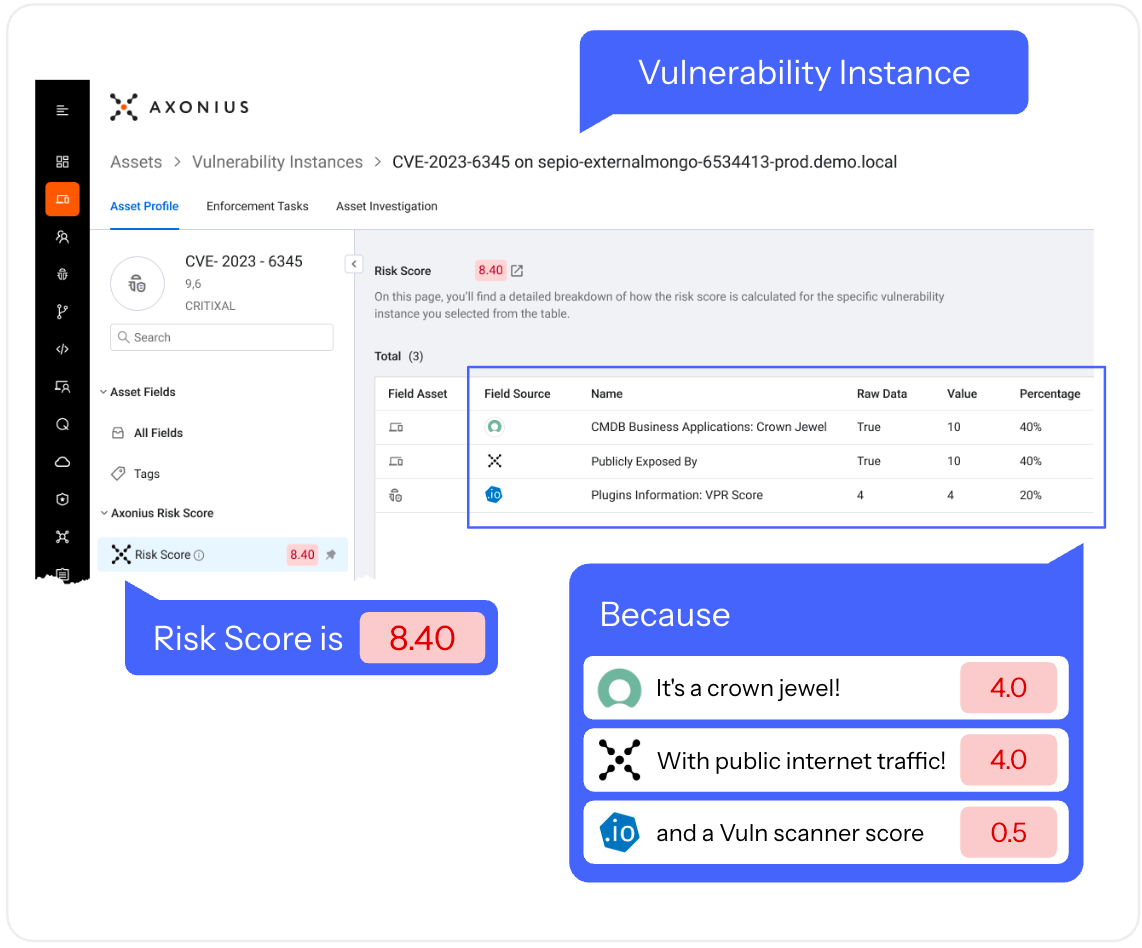
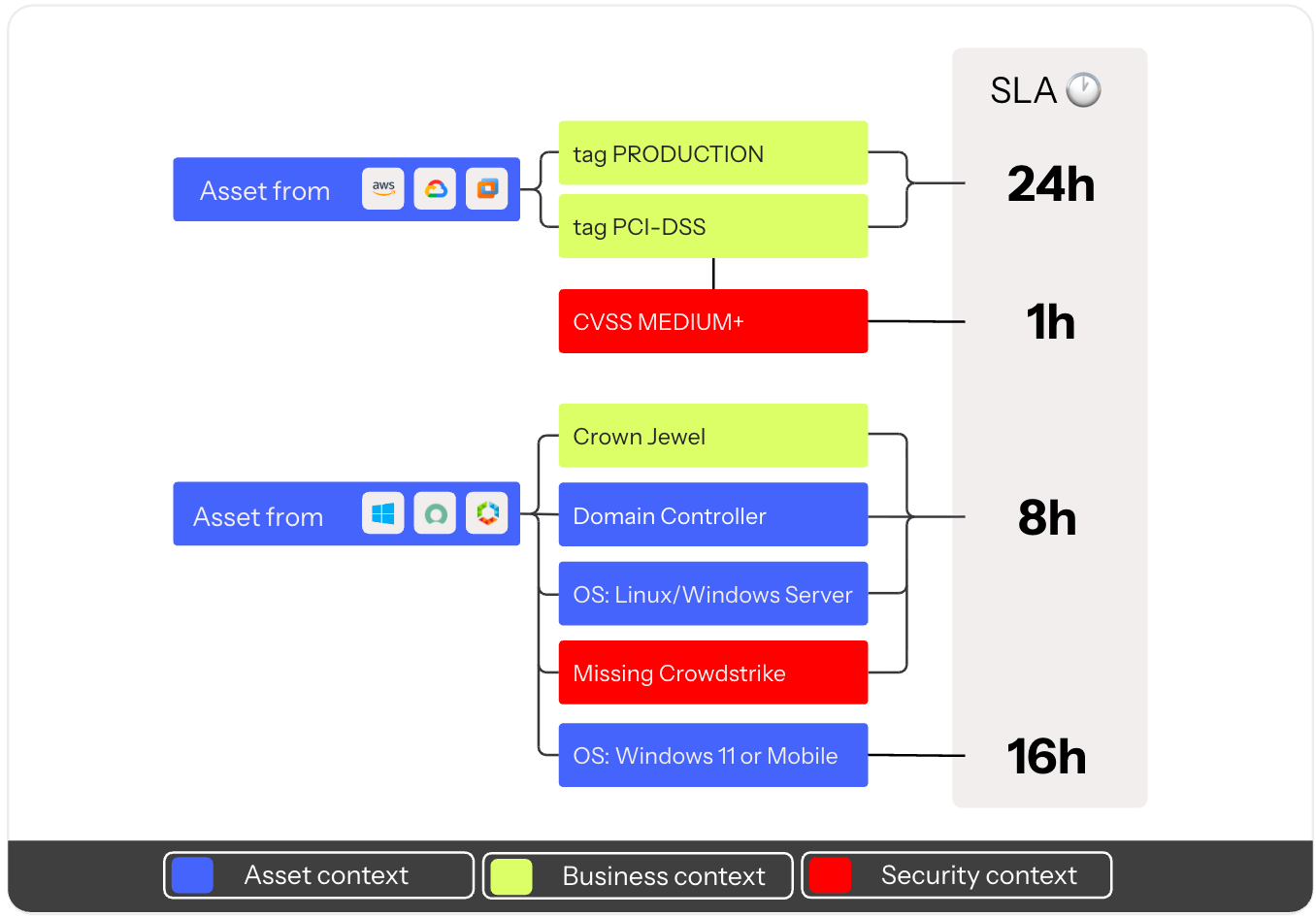
Also, coming soon is the ability to track custom SLAs based on the calculated risk score from different signals. A high-severity CVE is one thing, but a high-severity CVE on an asset tagged as PCI-DSS running in production is another thing. With SLAs, you’ll be able to measure against mean-time-to-all-the-things: detect, assign, and remediate.
All eyes on how to mobilize
The point of actionability is, well… taking action. Exposures come in many forms, as do actions. While the promise of the future is to automate all the things all the time, the reality is that there are different mobilization modes fit to the issues, the assets, the criticality, and the tasks at hand.
Whether it’s an agentic workflow, pre-defined automation, or manual runbooks, actions follow.
The results
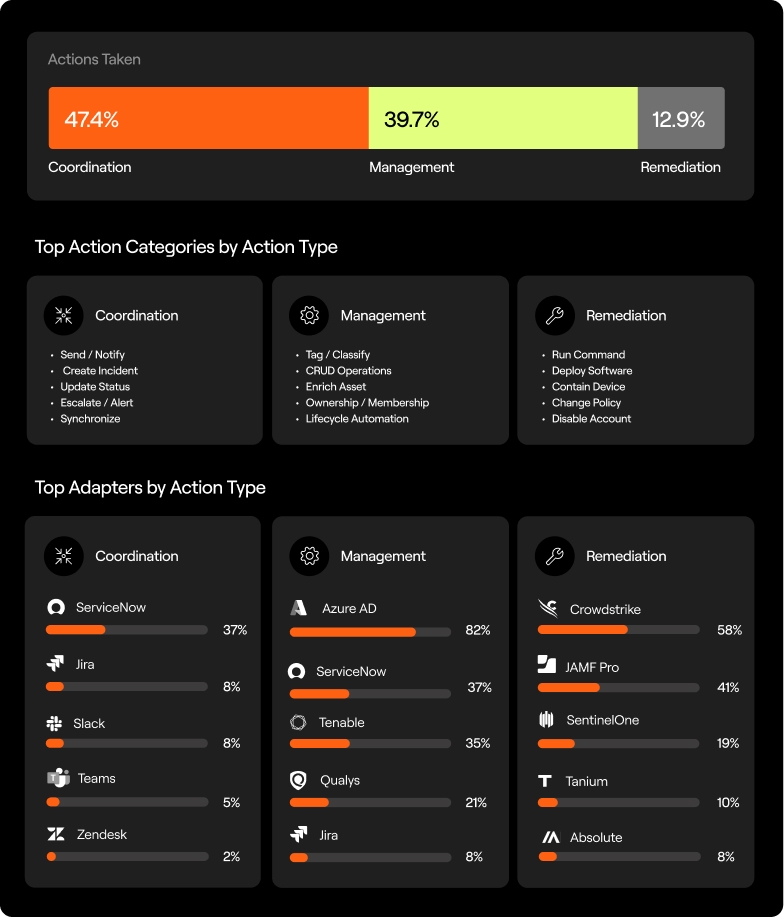
When we looked at the actions taken in Axonius, we saw a pattern across three mobilization modes:
Coordination: Notifications, ticket creation, ownership assignment, and escalation, all key to ensuring nothing falls through the cracks.
Management: Continuous lifecycle actions like tagging, enrichment, CRUD operations, and ownership updates triggered by asset events.
Remediation: Direct actions on assets like running commands, deploying software, changing policies, and disabling accounts. These tend to be more sensitive, hence more targeted.
What this tells us is that most activity today is focused on setting the table for action: routing issues to the right people, enriching them with context, and managing asset states. That’s not a flaw; it reflects how security work actually gets done in complex environments. Before you touch a production system, you want confidence in ownership, impact, and timing.
The opportunity
The next evolution is bringing confidence to remediation. As teams grow more comfortable with the context, conditions, and constraints around their environments, we expect to see a more balanced distribution of actions, with more issues being resolved directly and automatically through well-defined remediation operations (RemOps).
This doesn’t mean every action gets automated overnight. It means more issues can move from “assigned and waiting” to “handled and closed” with fewer handoffs. That’s where well-defined triggers, conditions, and orchestration come into play.
Axonius pro tip
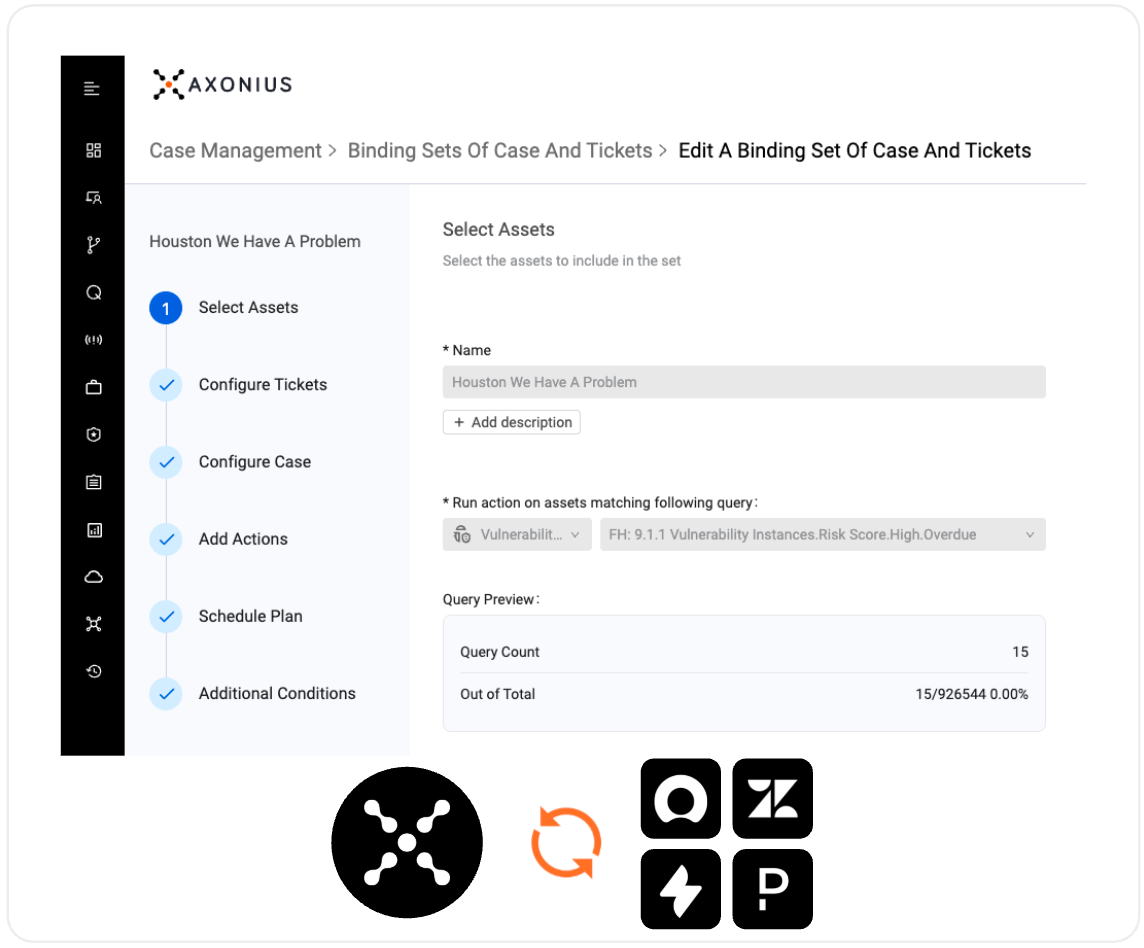
Most IT and security teams already rely on ticketing systems to mobilize work, but did you know that with Axonius, you can bi-directionally synchronize external tickets with Cases, keeping query state and ticket state continuously aligned?
For example, during a patch management exercise for EOL software, you can bind a Case in Axonius to a ticket in ServiceNow, Jira, or Zendesk. As assets are remediated, every discovery cycle updates the Case, which then syncs downstream to the ticket. Reach full coverage? The ticket closes automatically. Boom.
Wrap it up
The data tells us that cybersecurity teams are doing a lot right. You love to see it. Achieving high agent coverage at a massive scale, stitching together context from a wide mix of tools, and mobilizing action through coordination and lifecycle management: that’s no small feat. But what it does is set you up for more proactive cyber resilience across your entire environment.
The Axonius Adapter Network offers just one lens into the state of actionability, but it’s a powerful one. It reflects how teams work in practice: pulling in the signals they trust, operationalizing them, and closing the gap between knowing and doing. And most importantly, doing so at the aggregate in one place.
This data study is only the beginning. We’re going to dig deeper into the data, looking for patterns and surfacing insights that help teams move faster, act smarter, and drive actionability along the way.
If you want to get your own numbers and apply these learnings to your environment, book a personalized demo with us!
Categories
- Asset Management

Get Started
See how to make asset intelligence actionable with a guided demo:
- Stop chasing data — work from one asset model your entire team can trust.
- See what's exposed before it's a problem — surface coverage gaps automatically.
- Turn alert noise into action — cut thousands of alerts down, to the ones that matter.