Practical guide to AI-ready exposure management with Axonius (Mythos included)

Ivan Dwyer
Principal Product Marketing Strategist, Axonius

Pop quiz. What’s moving faster: vulnerabilities or news about vulnerabilities? There is no wrong answer.
Between the Claude Mythos announcement and the NIST NVD pullback, the takeaway is clear: security programs built for human-speed disclosure won't survive machine-speed discovery.
At the same time, nothing is materially new: volumes of vulnerabilities have been rising for years, and teams have been placing more emphasis on proactive security operations to address the wave.
Every prediction has already been made. Let’s put aside the hype and break down how customers leverage Axonius for their exposure management programs. This practical guide is our recommendations for answering the inevitable Board question, “is our security program AI-ready?” (or "is our security program Mythos ready?" if you're answering the news cycle)
We recommend five actions to take with Axonius right now.
Treat exposure management like incident response. Bring the same rigor of severity tiers, SLAs, owners, and validation to every security finding. Process findings as they arrive, not on a cycle.
Scope exposures beyond CVEs. Misconfigurations, coverage gaps, and identity risks don't have CVE identifiers and never will. Define toxic combinations as tracked findings so they carry the same weight as scanner-reported vulnerabilities.
Weigh your context to the business. CVSS, EPSS, and KEV are useful inputs, not sufficient answers. Layer security, asset, and business context with custom weights so prioritization reflects your environment, not a generic score.
Automate ownership assignment. Mean Time to Ownership determines whether SLAs are achievable or aspirational. Attach owners to findings automatically based on discovery criteria – the target is near-zero.
Contain first, remediate next, validate always. Scope blast radius before assigning the fix. Pre-configure mitigation and remediation paths. Track verified remediation rate, not ticket closure.
The full guide is below, with practical "how-to" steps for each recommendation.
1. Treat exposure management like incident response
A typical patching exercise assumed a predictable cadence. Patch Tuesday is as common as Taco Tuesday - tequila optional, but encouraged. There was the occasional zero-day that disrupted that cadence, but the assumption moving forward is that rapid response is the default.
Think about how your organization runs incident response: severity levels, runbooks, owners, SLAs, post-incident validation. Bring this rigor to exposure management, where every security finding is triaged, owned, tracked, and validated as it surfaces. It’s still proactive as the aim is to get ahead of exposures before they become exploits, but the shift is towards more continuous, real-time investigations.
Incident response teams run to the SIEM. Exposure management teams run to Axonius where all findings are reconciled across systems and enriched with all the context.
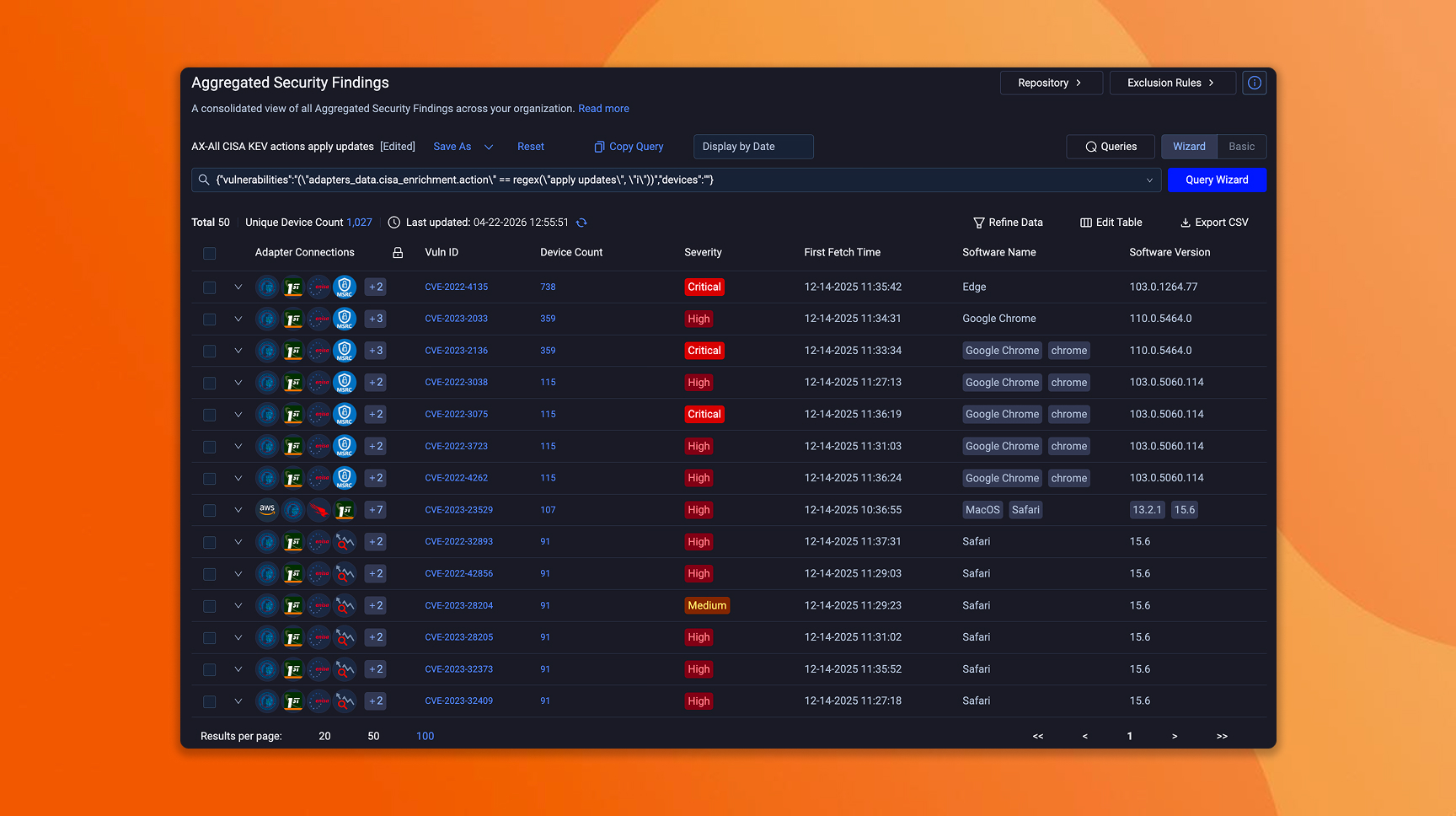
What to do in Axonius
Connect your security tools and establish a unified findings view: Most teams are already aggregating findings from their primary scanner and maybe one or two other sources. That's a reasonable starting point. What changes now is the coverage expectation. Axonius ingests from 150+ sources across scanners, CNAPP, identity providers, application security platforms, and more, correlating every finding to the assets it affects and enriching with context on ingestion. When disclosure volume climbs, the unified view is what keeps triage from fragmenting across consoles and spreadsheets.
Define severity tiers and SLA targets that mirror your incident response model: If you already have exposure SLAs, you're ahead. The shift is recalibrating them for shorter exploitation windows. P1 exposures that carried a 7-day SLA when exploit development took weeks may need to be compressed to 24–48 hours when exploit generation is automated. If you don't have exposure SLAs yet, borrow your incident response tiers as a starting point, codify them in Axonius, and attach them to findings automatically based on your scoring model.
Assemble dashboards that track exposure operations in real time: Weekly reporting was adequate when the exposure landscape moved weekly. It isn't when findings arrive continuously and exploitation timelines compress to hours. Axonius dashboards surface open findings by severity, SLA status, ownership coverage, and aging into a live operational view rather than a retrospective slide deck. If a P1 finding has been open 48 hours without an owner, that's visible and escalated now, not surfaced at the next team sync.
“We are using these foundational capabilities in Axonius to drive automated alert notification for leadership and engineers to effectively respond to zero-day threats. We’re automating most of the zero-day response using a chatbot that sits on top of Axonius.” - Geoff Krahn, Director of Product and Platform Security, Lumen Technologies
2. Scope exposures beyond CVEs
Not every exposure is a vulnerability and not every vulnerability is an exposure. CVEs get the headlines, but they represent one category of exposure.
Coverage gaps, misconfigurations, policy violations, and identity risks are all exposure conditions that carry real operational consequences. An endpoint missing CrowdStrike is exploitable. An S3 bucket open to the internet is exploitable. An admin account without MFA is exploitable. None of these have CVE identifiers, EPSS scores, or NVD enrichment, and they never will. NIST stepping back from universal CVE enrichment is a real problem, but focusing only on that gap misses the fact that most of the exposure surface was never in the NVD to begin with.
This is where unified findings matter again. Here, the emphasis is on not letting any single source define what an exposure is. A scanner reports CVEs. A CNAPP reports cloud misconfigurations. An identity provider reports access anomalies. Each one is correct within its domain but incomplete on its own. The exposures that carry the most risk are often the ones that cross domains – a vulnerable server that's internet-facing, missing endpoint protection, and accessible by a privileged identity with stale credentials. No single tool sees that combination. Axonius does, because we reconcile findings across all of them.
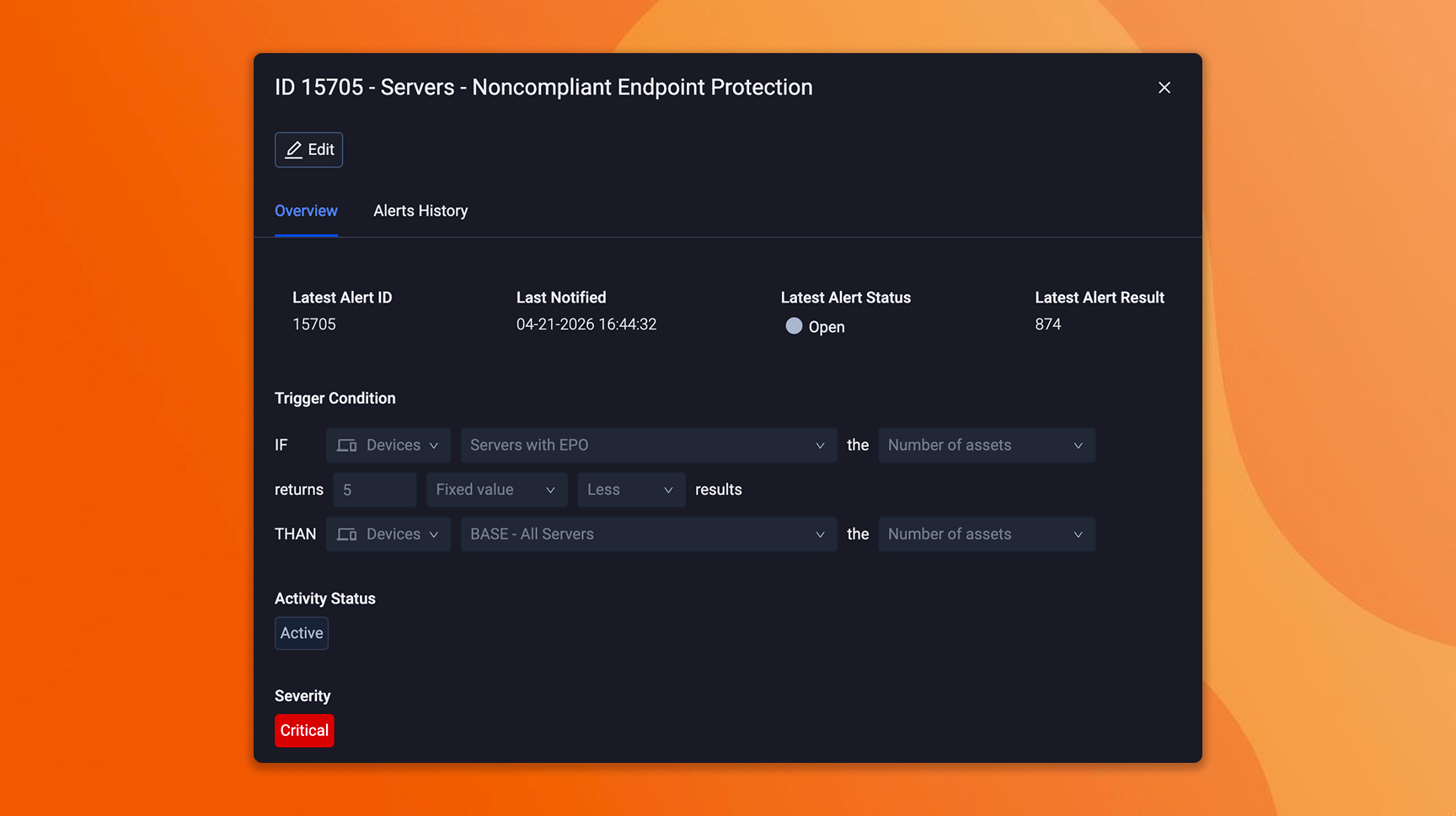
What to do in Axonius
Bring all exposure types into one prioritized view: It’s common to prioritize CVEs in one workflow and handle coverage gaps, identity risks, and misconfigurations separately in different dashboards, different owners, different cadences. That was manageable at lower volumes, but when finding counts climb and the most dangerous exposures are compound conditions that cross those boundaries, parallel workstreams can't produce a coherent priority stack. Axonius puts every finding type into the same scoring model so a coverage gap on a crown jewel and a critical CVE on a test server are evaluated in the same queue. The programs that triage holistically will move faster than the ones reconciling three separate priority lists after the fact.
Audit your current findings sources: As Mythos-class discovery surfaces vulnerabilities across every OS and browser, the exposures that compound those findings (missing endpoint agents, ungoverned identities, unmanaged SaaS) become more dangerous. Map the exposure categories your program cares about against the sources currently connected. If endpoint coverage validation, identity posture, or software lifecycle status are absent, those are the gaps that turn a disclosed CVE into an exploitable path.
Define your top toxic combinations: Many teams already track coverage gaps and misconfigurations, even if it's a spreadsheet of assets missing EDR or a periodic identity access review. That's a solid instinct and a strong starting point. The next step is making those conditions generate tracked findings automatically so they carry the same weight as scanner-reported CVEs. Define compound conditions as Saved Queries and/or Findings in Axonius – internet-facing plus missing EDR, privileged account plus no MFA, production workload plus EOL/EOS software.
“Axonius exposes misconfigurations and unpatched software instantly. Instead of waiting for the next audit cycle, we can remediate vulnerabilities as soon as they surface.” Matt Durant, CISO, BlueLinx
3. Weigh your context to the business
Learning how LLMs work has been eye-opening for all of us – or it’s just magic. One key takeaway is that weights and biases determine the quality of the output. The same applies to risk scoring.
EPSS predicts exploitation likelihood over 30 days using historical data. CVSS scores technical severity without any awareness of the environment. KEV confirms active exploitation but skews toward perimeter-facing CVEs visible in federal network telemetry. Feed a model incomplete inputs with no weighting, and the output is noise. That's true for LLMs and it's true for your prioritization model.
This is where durable context earns its place. The asset and exposure model that Axonius continuously reconciles across your stack is the prerequisite for prioritization that holds up under volume. Every finding carries the full weight of what it affects and why it matters. That's the difference between raw data and decision-grade asset intelligence.
Axonius risk scoring layers every external signal with three dimensions of context that only your environment can provide:
Security context: What did the security tools report? CVEs, misconfigurations, severity scores, threat intelligence, exploitation status. This is the starting input most programs already have.
Asset context: What is this asset and what's its state? Is EDR active? Is it internet-facing? What does it connect to? Who has access? Are there compensating controls, or is this exposure unmitigated? This is the layer that turns a reported finding into a scoped problem.
Business context: Is this asset tagged as a crown jewel in ServiceNow? Is it marked as production in AWS? Does it support a revenue-critical process? Who owns the business outcome it supports? This is the layer that determines whether a scoped problem is a priority.
Axonius lets you assign custom weights and define conditional logic that reflects your risk posture. A CVSS 7.2 on a production crown jewel missing endpoint protection outranks a CVSS 9.8 on an isolated dev server with full control coverage. An EPSS score of 0.6 on an internet-facing asset with a privileged identity attached is a different problem than the same score on an internal asset behind segmentation. The scoring model makes those distinctions operational rather than theoretical.
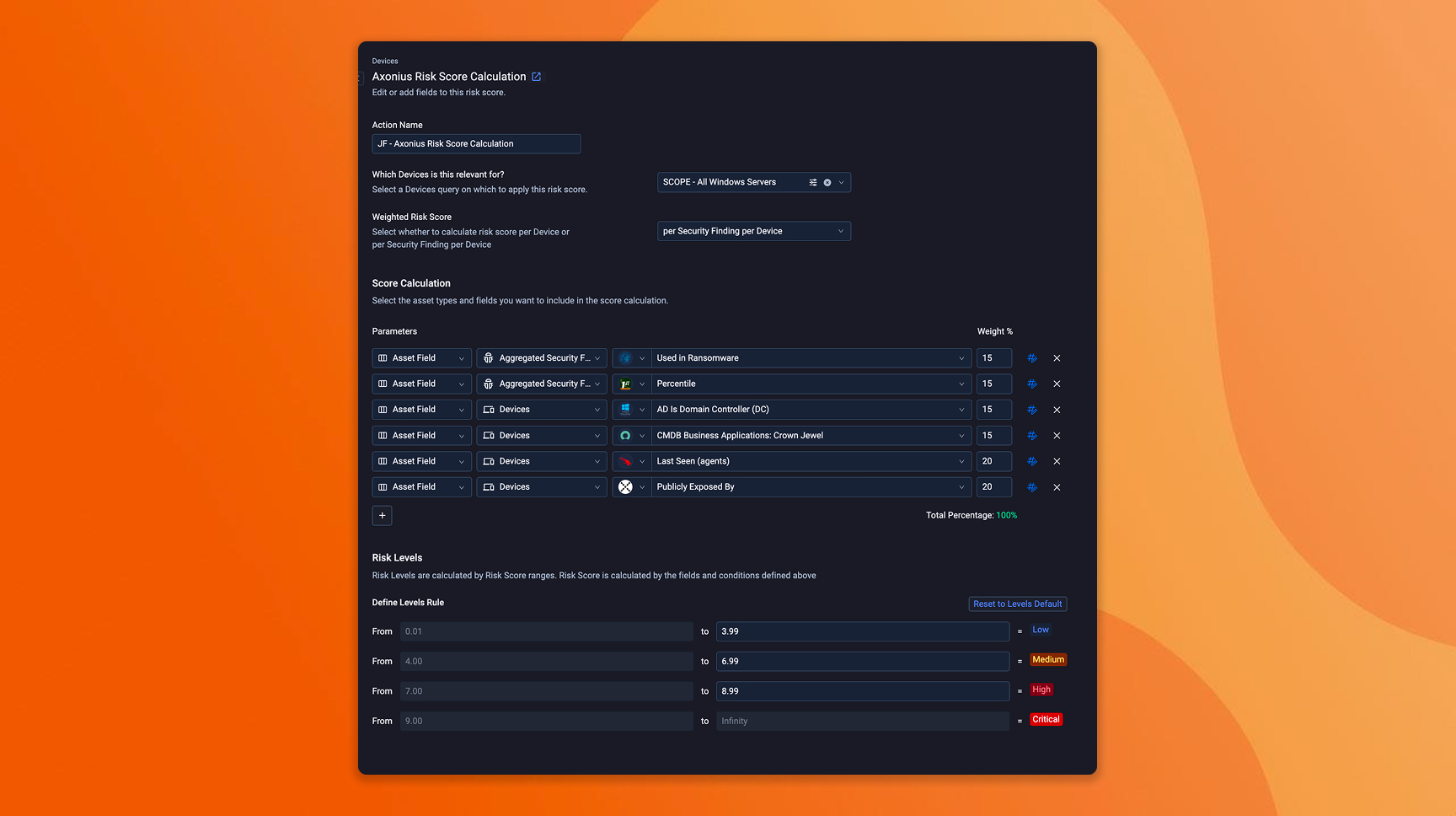
What to do in Axonius
Review your current scoring model and identify where it's running on defaults: CVSS severity as the primary input is a reasonable baseline. The shift now is that CVSS alone can't absorb the volume ahead. When thousands of findings score as critical, you need the tiebreakers that CVSS can't provide. Layer in EPSS, KEV, and any third-party threat intel feeds you subscribe to as additional scoring inputs. These external signals give you exploitation likelihood and confirmed activity alongside technical severity.
Add business and asset context as weighted inputs: Pull crown jewel designations from ServiceNow, environment tags from AWS or Azure, and control coverage status from your endpoint and identity tools. These are the inputs that separate a critical finding on a test server from a critical finding on the system that processes customer payments. If your organization already maintains business-criticality classifications somewhere – CMDB, cloud tags, internal wikis – bring them into the scoring model so they carry weight automatically rather than requiring manual triage judgment on every finding.
Define conditional escalation rules for your highest-risk combinations: This is where the scoring model gets sharp. Build rules that escalate severity when specific conditions compound: internet-facing plus missing agent, privileged identity plus stale credentials, production workload plus unpatched critical CVE plus no compensating control. Test the rescored output against your last quarter's remediation queue – what moves up, what moves down, and do the new priorities match what your team would have escalated manually? That comparison is the calibration step where confidence in the model is built.
“When you have a clear picture on the scope and domain of what you're protecting, then your strategy and your program is very targeted and very accurate. The information we get from Axonius supports this process.” - Tim Lee, CISO, City of Los Angeles
4. Automate exposure ownership assignment
AI compressed the time between disclosure and exploitation. It also compresses the time between "who owns this?" and "who is accountable for this?"
When finding volume is manageable, ownership can be negotiated per issue – a Slack thread, a ticket reassignment, a weekly sync. When volume climbs, that negotiation becomes the bottleneck. The metric that exposes this: Mean Time to Ownership. How long between a finding surfacing and an owner being attached? In most programs, the honest answer is days. The target is near-zero.
Ownership also isn't a single role, and treating it as one is where programs get tangled. The asset owner who maintains the system isn't always the business owner accountable for the workload, who isn't always the remediation owner responsible for applying the fix. A coverage gap on a cloud workload might involve a platform team, an application owner, and a security engineer – each with a different piece of the response.
Axonius makes ownership assignment automatable and configurable. Customers build rules based on discovery criteria – business unit tags, adapter source, cloud account, asset type, environment classification, location, etc. When a finding surfaces, it arrives with the right owner already attached based on conditions the team defined in advance.
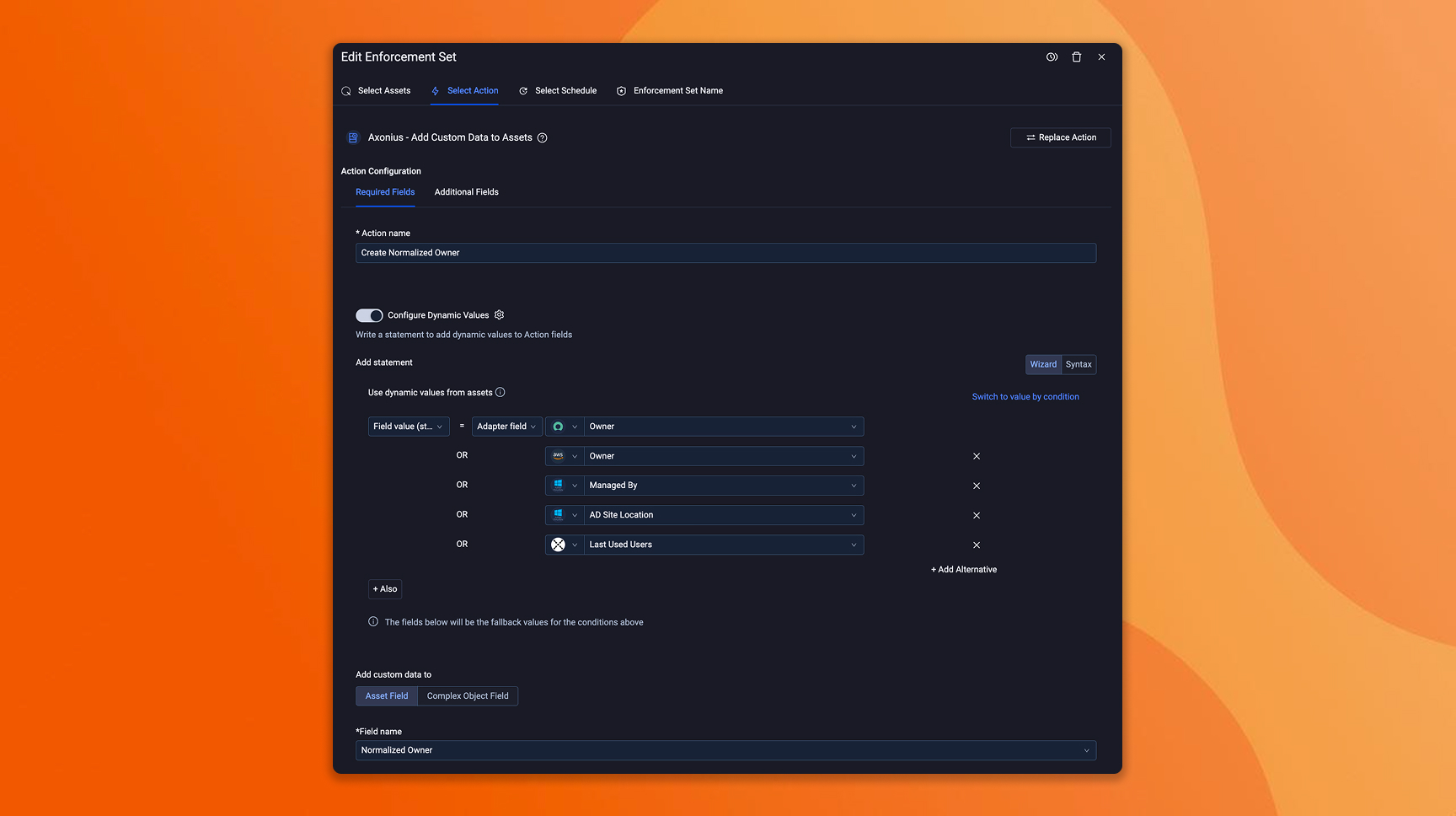
What to do in Axonius
Audit your current ownership coverage: What percentage of assets in Axonius have an assigned owner today? For many of our customers doing this for the first time, the number is lower than expected – always an eye-opening exercise. This is the gap that determines whether your remediation SLAs are achievable or aspirational.
Build automated assignment rules based on criteria you already have: Most organizations already maintain ownership signals somewhere — business unit tags in the CMDB, account ownership in cloud providers, team assignments in identity tools. Bring those into Axonius as assignment criteria so ownership populates automatically on discovery. Start with your highest-severity asset populations and expand from there.
Define which ownership roles your program needs and track them separately: Asset owner, business owner, remediation owner – decide which roles matter for your operating model and configure them in Axonius. Tracking Mean Time to Ownership alongside Mean Time to Remediate surfaces whether your program is stalling on the fix or stalling on figuring out who fixes it. If ownership assignment takes days, your SLAs are already broken before the remediation work begins.
“People respond better when they’re given accurate, contextual information instead of vague security alerts. That reduces resistance and improves cooperation.” - Kara Keene, Senior Manager of Attack Surface Reduction, TransUnion
5. Contain first, remediate next, validate always
Everything covered so far – unified findings, broader exposure scope, weighted prioritization, automated ownership – exists to solve the remediation challenge, but the new reality is you won’t be able to remediate everything at once. When everything is critical, nothing is. The first instinct should be to contain the issue, then work towards the fix.
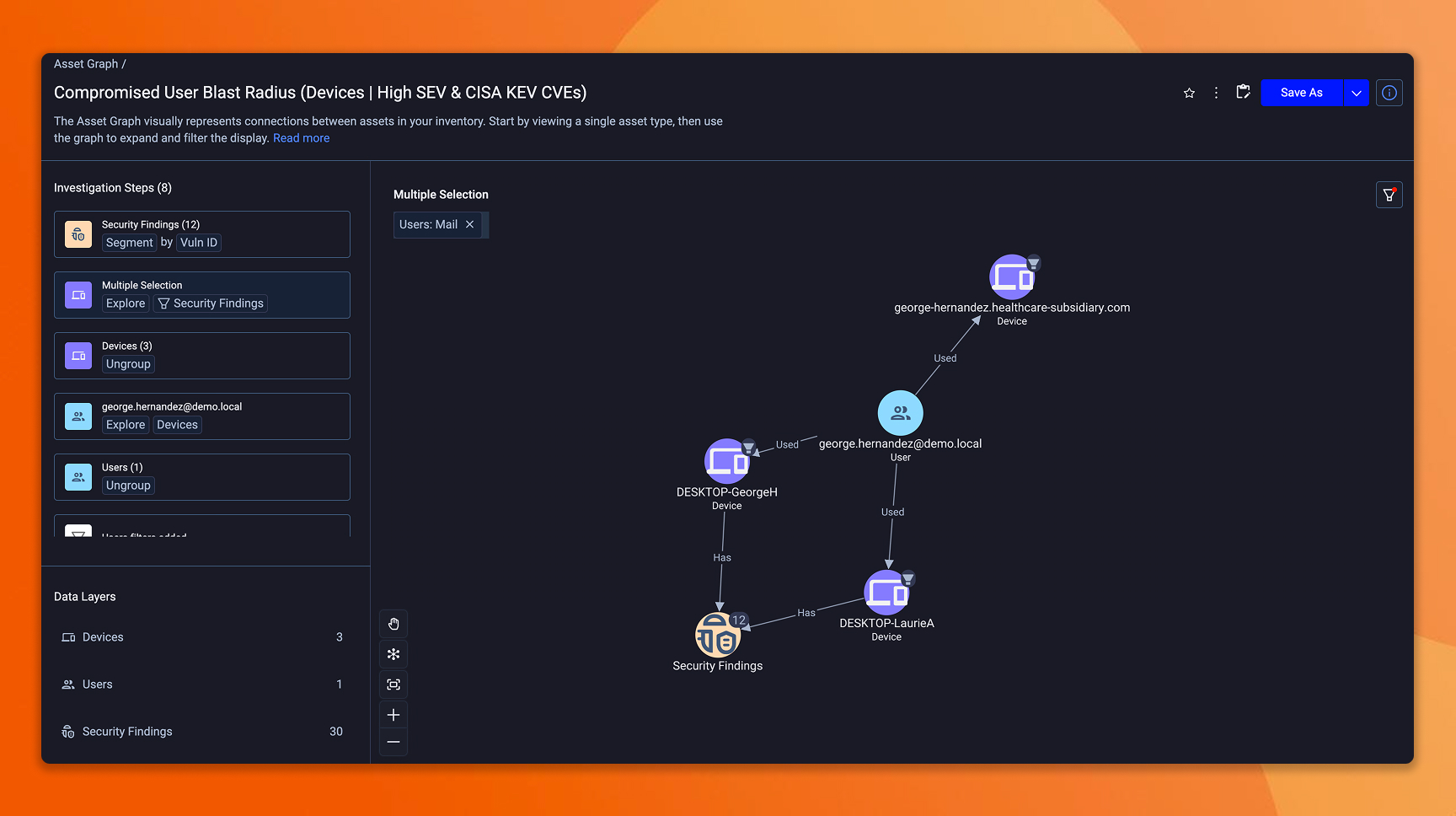
This is where the prior investments pay off together. Your unified findings view tells you the exposure exists. Your scoring model tells you how critical it is in your environment. Your ownership model tells you who's accountable. What you need now is the answer to a different question: if this exposure is exploited, what's the blast radius? Which systems are reachable? Which identities are involved? What breaks downstream?
Answering that requires a model of how assets relate to each other. Axonius models these relationships as a knowledge graph – users on devices, users assigned to applications, app extensions tied to parent apps, infrastructure dependencies, etc. Network Routes show whether an asset is publicly exposed and trace the path through firewall rules and load balancer configurations to the underlying assets. Together, these answer the containment questions before remediation begins.
Identity deserves special attention here. A compromised identity is often both the target and the entry point. Axonius correlates identities with the devices, applications, and infrastructure they can access, so when an identity-based exposure surfaces, you see the full reach across the environment, not just the identity record in isolation.
This clear understanding of impact and reach provides two clear action paths: mitigation or remediation. Knowing which to do and how is a function of everything built up to this point. The scoring model tells you how urgent it is. The ownership model tells you who mobilizes. The blast radius assessment tells you what to protect while the fix is in flight.
Axonius supports every mobilization path from one place. The Action Center handles 600+ direct actions for automated fixes where it's safe, and creates tracked tickets with full context, owners, and SLAs through ServiceNow, Jira, or whatever system your teams already use when coordination is required. Customers configure which approach applies to which conditions based on the issue at hand. And every action is validated continuously. When a mitigation or remediation is applied, Axonius re-evaluates the asset against the original finding. If the exposure persists, it resurfaces. The loop closes at verification.
What to do in Axonius
Model reach for your highest-severity exposures: Use asset relationships and Network Routes to identify which systems are reachable from the exposure, which identities have access, and where control gaps exist along the path. Start with internet-facing assets with control gaps – these are where containment assessment matters most and where the speed of exploitation makes the reach question urgent rather than optional.
Configure your mitigation and remediation paths in the Action Center: The key is formalizing which conditions get automated versus coordinated, and having both paths ready before the finding arrives. Define the criteria: automated for low-risk, high-confidence fixes; tracked tickets with context and SLAs for changes that carry operational risk. When volume spikes, the teams that pre-configured these paths mobilize immediately.
Track remediation closure: The common measure to track is Mean Time to Remediate. The gap is that MTTR typically measures when the ticket closed, not whether the exposure is actually gone. Set up validation dashboards that track remediation effectiveness – findings resolved and confirmed resolved by continuous re-evaluation. Identify your top recurring exposures (resolved and resurfaced within 30 days) and investigate whether the fix is lapsing, the control is drifting, or the remediation was incomplete. The metric that matters for board reporting is verified remediation rate, and Axonius is where that number comes from.
“Axonius compresses that ‘figuring it out’ phase so the team can move faster on remediation and containment.” - Alyssa Miller, CISO, Epiq
Where does your program stand on the AI-readiness curve?
We’ve covered a lot so far. If you made it this far, kudos to you (or your AI). Let’s close with a quick self-assessment across five dimensions:
- Foundation: What percentage of your assets are in a continuously reconciled inventory? Are you tracking beyond devices – identities, software, SaaS, cloud workloads? Is ownership assigned to more than 90% of assets?
- Coverage: Are you validating controls continuously or at audit time? Can you measure coverage drift rate – the percentage of assets that lost a control in the last 30 days? Are you tracking toxic combinations – compound conditions where misconfigurations, coverage gaps, and vulnerabilities intersect as findings alongside scanner-reported CVEs?
- Prioritization: Is your scoring model CVSS-only, or are you layering security, asset, and business context with custom weights and conditional logic? Can you distinguish between a critical CVE on a production crown jewel and the same CVE on an isolated dev server?
- Containment: Can you scope blast radius from a critical exposure before assigning the fix – which systems are reachable, which identities are involved, what breaks downstream? Are mitigation and remediation paths pre-configured, or decided per-issue? Are you tracking verified remediation rate through continuous re-evaluation, or relying on ticket closure?
- Downstream alignment: Are SOC, CMDB, risk management, and executive reporting consuming reconciled data from Axonius, or operating from independent sources?
If you’re scoring well across these dimensions, you are operationally ready for the volume ahead. We don’t know what we don’t know, but these fundamentals make a strong security program no matter the day’s news. If you see gaps here, fear not – you know where to invest next, and have a solid blueprint to get you there.
Here’s to the AI era. What a time to be alive.
Categories
- Threats Vulnerabilities
- Artificial Intelligence Ai

Get Started
See how to make asset intelligence actionable with a guided demo:
- Stop chasing data — work from one asset model your entire team can trust.
- See what's exposed before it's a problem — surface coverage gaps automatically.
- Turn alert noise into action — cut thousands of alerts down, to the ones that matter.